Réécriture de requêtes pour la recherche documentaire selon une methode de classification à base d'arbres de décision non-supervisé
ECRITURE DE REQUˆ
ETES POUR LA RECHERCHE
DOCUMENTAIRE SELON UNE M´
D'ARBRES DE D´
ECISION NON SUPERVIS ´
Sous la direction de Patrice Bellot et Marc El-B
Laboratoire d'Informatique d'Avignon
Une difficult´e majeure dans l'utilisation d'un syst eme de recherche documentaire est le choix du vocabulaire aemployer pour exprimer une requˆete. L'enrichissement de la requˆete peut prendre plusieurs formes : ajout demots extraits automatiquement des documents rapport´es, r´eestimation des poids attribu´es a chacun des motsde la requˆete initiale,
etc. Le syst eme de recherche documentaire SIAC est utilis´e pour extraire un premierjeu de documents a partir d'une requˆete. Une m´ethode de classification non supervis´ee, a base d'arbres ded´ecision, est ensuite exploit´ee pour classer les phrases des documents trouv´es et les documents eux-mˆemes, selonqu'elles/ils contiennent ou non certains mots extraits automatiquement de l'ensemble des documents rapport´es.
A chaque nœud de l'arbre, peut ˆetre associ´ee une expression bool´eenne mettant en jeu les mots s´electionn´eslors de la classification. Nous montrons, a l'aide des donn´ees de la seconde campagne d'´evaluation Amaryllis,que la r´e´ecriture de la requˆete suivant les expressions bool´eennes correspondant aux meilleures feuilles permetd'am´eliorer la pr´ecision de la recherche documentaire. La r´e´ecriture de la requˆete, au vu de la structure desarbres de d´ecision, am ene a se pencher sur le traitement de la n´egation dans les syst emes de recherche ainsi qu' aune reformulation des crit eres de pond´erations habituellement utilis´es.
Ce m´emoire pr´esente l'exploitation d'une m´ethode non supervis´ee de classification de textes pour
l'enrichissement de requˆetes dans une application de recherche documentaire. Dans ce premier chapitre,les notions inh´erentes a ce travail sont pr´esent´ees, c'est a dire les syst emes de recherche documentaire,l'enrichissement de requˆetes et la m´ethode de classification. Seront ´egalement explicit´es les crit eres etle contexte de l'´evaluation des m´ethodes d´evelopp´ees. Le deuxi eme chapitre, pr´esente les hypoth eses etpropose les mod eles qui seront ´evalu´es puis analys´es dans le chapitre 3. Le dernier chapitre abordera lesperspectives et concluera.
EMES DE RECHERCHE DOCUMENTAIRE ET
LEUR PRISE EN COMPTE DE LA N´
Un syst eme de recherche documentaire permet a un utilisateur qui soumet une requˆete de rechercher
et retrouver les documents jug´es pertinents par rapport a cette requˆete. La pr´esentation de ces r´eponsesest ordonn´ee en fonction du calcul d'une similarit´e entre les documents et la requˆete. La requˆete est laformulation de ce que veut trouver l'utilisateur. La plupart des syst emes se basent sur les mots communs
a la requˆete et aux documents pour effectuer leurs recherches. Or, l'utilisateur pourrait ´egalement vouloir
pr´eciser certaines notions qu'il ne veut pas retrouver, par exemple "
Je d´esire des textes au sujet de lar´eaction de fusion atomique, le ph´enom ene de fission ne m'int´eresse pas". Il serait alors particuli erementint´eressant d'introduire dans la requˆete des mots exprimants un point de vue "n´egatif" nuanc´e (car des
CHRISTIAN RAYMOND
documents parlant a la fois de fusion et de fission peuvent ˆetre int´eressants) afin de rejeter plus oumoins fortement certains documents (dans l'exemple le mot "fission"). Certains mod eles de syst emesde recherche prennent en compte le traitement de la n´egation comme les mod eles bool´eens fond´es surl'alg ebre de Boole et les mod eles flous bas´es sur la logique floue. C
¸ a n'est pas le cas des syst emes
vectoriels qui ne la prennent pas en compte naturellement.
ele bool´
L'interrogation bool´eenne est le type d'interrogation le plus r´epandu. Elle
s'appuie sur l'utilisation des op´erateurs logiques manipul´es grˆace a l'alg ebre de Boole. Elle consiste aformuler une question avec une liste de termes s´epar´es par des op´erateurs logiques (ET, OU, NON),et a rechercher les documents correspondant a cette requˆete. Par exemple, pour la question "(moteurET Renault) ET NON(recherche)" le syst eme doit fournir comme r´eponse tous les documents de labase contenant les deux termes "moteur" et "Renault" ne contenant pas "recherche". De tels syst emesont l'avantage de fonctionner en ´etant moins gourmands en ressources physiques et en puissance decalcul que d'autres syst emes, c'est pourquoi ils sont utilis´es, a l'heure actuelle, par un grand nombrede moteurs disponibles sur Internet (Alta Vista, Excite, Galaxy, HotBot,
etc.). Mais, en contrepartie, cessyst emes ne permettent pas d'exploiter les requˆetes en langage naturel. La similarit´e entre la requˆeteet les documents est donn´ee par le nombre de mots communs entre ceux ci, ce qui ne permet pas unclassement tr es performant des documents en fonction de leur pertinence (beaucoup de documents seretrouvant avec le mˆeme indice de similarit´e). Quant a l'utilisation du NON, elle est ici beaucoup troprestrictive. En effet, tout document contenant le mot pr´ec´ed´e de NON sera exclu alors qu'il aurait pu
ˆetre tout de mˆeme pertinent. Dans l'exemple pr´ec´edent si l'utilisateur d´esirait avoir des informations sur
les "moteurs Renault", il a exclu le mot "recherche" pour ´eviter les documents ´evoquant les moteurs derecherche par exemple, tous les documents concernantla recherche pour d´evelopper les moteurs Renaultseront totalement exclus.
ele flou.
Le syst eme flou de recherche documentaire est vu comme une extension du mod ele
bool´een. Le mod ele flou permet, contrairement au mod ele bool´een, la prise en compte de la pond´erationdes requˆetes et de la pertinence partielle des r´eponses. C'est a dire, a quel degr´e le document est uner´eponse a la requˆete. Les syst emes flous de recherche documentaire ont un fonctionnement similaire auxsyst emes bool´eens, a la diff´erence qu'ils s'appuient sur une indexation non-bool´eene des documents,c'est a dire que l'on associe un poids aux mots, qui sont retenus pour repr´esenter le document, comprisentre 0 et 1 selon le degr´e de repr´esentation du mot pour le document en question. Cette pond´erationpermet de diff´erencier les mots des documents, des mots ´etant consid´er´es plus importants que d'autrescar plus caract´eristiques d'un document. Ces syst emes autorisent aussi une pond´eration des mots dela requˆete, de fac¸on manuelle toutefois. L'utilisateur pouvant indiquer l'importance des mots pr´esentsdans la requˆete. Ces pond´erations permettent d'obtenir un score de similarit´e requˆete document, comprisentre 0 et 1, r´ealisant un classement hi´erarchique de pertinence des documents que ne permet pas lemod ele bool´een. De plus, le traitement de la n´egation n'exclut pas inconditionnellement les documentsposs´edant les mots de la requˆete pr´ec´ed´es par l'op´erateur NON. Ils obtiennent seulement un score desimilarit´e inf´erieur. Les requˆetes exprim´ees en langage naturel (c'est a dire exprim´ee sous la forme d'unephrase et non sous la forme de mots clefs li´es par des op´erateurs logiques) ne peuvent ˆetre trait´ees parces syst emes.
Les syst emes vectoriels bas´es sur les propositions de Salton [Salton, 1971]
fonctionnent de la mani ere suivante : dans un espace a
n dimensions constitu´e de
Di documents iden-tifi´es par un ou plusieurs termes d'indexation
Tj, on peut pond´erer ces termes suivant une m´ethodecontinue (selon l'importance de l'indexation dans le document,
Tj prend une valeur plus ou moins im-portante entre 0 et 1). Dans ces syst emes, la requˆete de l'utilisateur est mod´elis´ee sous la forme d'unvecteur (
q1
, q2
, ., qt) o u
qi repr´esente le poids du
ie terme et on calcule chaque similarit´e
sj(
Q, Dj),o u
j repr´esente le
je document (j=1 ;2 ;. ;n). Les mesures de similarit´e sont nombreuses, telles le pro-duit scalaire ou le cosinus, pour en savoir plus voir [Baeza-Yates et Ribeiro-Neito, 1999]. Le syst emevectoriel adapt´e pour traiter les requˆetes en langage naturel, permet de classer les documents retrouv´esen fonction de leur pertinence par rapport a la requˆete. Comme il ne g ere pas les op´erateurs logiques et
ecriture de requˆ
etes pour la recherche documentaire selon une m´
a base d'arbres de .
notamment l'op´erateur NON, il ne prend pas en compte le fait qu'un mot puisse avoir une connotationn´egative.
Diff´erentes formulations de la pond´eration des termes sont propos´ees dans la litt´erature (voir par
exemple [Salton et Allan, 1994], [Harman, 1992], [Kwok, 1996]). Celle utilis´ee dans le moteur SIAC, enraison de la qualit´e dont elle a fait peuve dans de nombreux syst emes, tient compte du nombre d'appa-ritions du terme dans le document (ou la requˆete) et du nombre de documents qui contiennent ce termedans le corpus (elle est appel´ee TFIDF -
Term Frequency, Inverse Document Frequency-). Cette formu-lation fait l'hypoth ese qu'un terme est important dans un document donn´e, s'il apparaˆıt souvent dans cedocument et que peu de documents le contiennent [Sparck-Jones, 1972]. Cette pond´eration est d´efinie dela mani ere suivante :
T F IDF (
w, d)
T Fw,d.IDFw,d
T Fw,d.(log2
avec :
w un terme,
d un document,
T Fw,d le nombre d'apparitions de
w dans
d,
DFw le nombre dedocuments du corpus qui contiennent
w et
N le nombre total de documents dans le corpus.
QUELQUES M ´
ETHODES D'ENRICHISSEMENT DE
L'enrichissement des requˆetes consiste a ´etendre le nombre de mots de celle-ci afin de la rendre plus
performante pour retrouver les documents pertinents. L'enrichissement des requˆetes
(query expansion)fait l'objet de nombreuses ´etudes. Ces ´etudes portent sur l'ajout automatique de termes [Attar et Fraen-kel, 1977] grˆace a l'utilisation d'un thesaurus [Qiu et Frei, 1993]. L'enrichissement peut ˆetre ´egalementr´ealis´e par l'utilisateur (
manual relevance feedback) ou automatiquement (
automatic relevance feedback)en fonction des documents rapport´es lors d'une premi ere recherche ; la s´el´ection d'un document pertinentpeut servir de r´ef´erence pour l'ajout de nouveaux mots par exemple (cf. [Salton, 1971] ou [Robertson etSparck-Jones, 1976]).
ETHODE DE CLASSIFICATION NON
SUPERVIS ´
Le syst eme SIAC (
Segmentation et
Indexation
Automatique de
Corpus) d´ecrit dans [Bellot, 2000]
permet de classer les documents qui ont ´et´e retourn´es a partir d'une requˆete. Cette classification estfaite a l'aide d'un arbre de d´ecision (
Semantic Classification Tree (voir [Kuhn et De Mori, 1995])) non-supervis´ee.
Arbre de d´
Pour construire un tel arbre, on doit d´efinir [Breiman et al., 1984] :
– un ensemble de questions a poser aux individus (ici phrases des documents trouv´es ou les docu-
ments eux mˆemes) ; nous choisissons des questions telles que chaque individu peut y r´epondre parl'affirmative ou la n´egative ; suivant sa r´eponse, l'individu est transf´er´e dans le nœud fils correspon-dant a la r´eponse "OUI" ou dans le fils correspondant a la r´eponse "NON"
– une r egle pour d´eterminer les questions a poser aux individus ;– un crit ere d'arrˆet d´eterminant l'ensemble des feuilles de l'arbre.
ees aux individus.
A chaque nœud de l'arbre, une question de la forme "
les
individus contiennent-ils le terme x ?" est pos´ee a chaque individu de ce nœud. Cette question permet desubdiviser le nœud courant en deux nœuds fils qui comprennent respectivement les individus du nœudcourant qui contiennent et qui ne contiennent pas le terme x. Dans notre cas, x d´esigne n'importe quelterme pr´esent dans l'ensemble des documents a classer.
A chaque nœud de l'arbre, il faut calculer quel
est le terme x qui conduit a la meilleure r´epartition en deux sous-partitions des individus de ce nœud.
ere de s´
election des questions.
Le crit ere de s´election d'une question est souvent fonc-
tion du gain en entropie observ´e avant et apr es l'affectation des individus dans de nouvelles partitions
CHRISTIAN RAYMOND
suivant la question consid´er´ee (´equation (15.3)). Un deuxi eme crit ere sera utilis´e, le crit ere de Gini(´equation(15.4)). L'entropie (ou l'indice de Gini) d'une partition
S compos´ee des classes1
c1
, c2
, ., ckde probabilit´es respectives
p1
, p2
, ., pk est d´efinie par :
Entropie :
HS =
−pi. log2
pi
Indice de Gini :
GS = 1
−
Les probabilit´es utilis´ees dans le calcul de l'entropie ou de l'indice de Gini sont celles que la requˆete soit
g´en´er´ee a partir des textes du nœud consid´er´e. Cette probabilit´e
p est calcul´ee en fonction d'un mod eleunigramme (voir formule 15.5).
Soient
r la requˆete,
wj le
je terme de
r,
Sn un nœud de l'arbre,
Ii un individu et
Z(
wj, Ii) le nombred'apparitions de
wj dans les individus de
Sn. Les signes
sont utilis´es pour repr´esenter la taille d'unindividu (le nombre de termes (occurrences) qu'il contient).
p(
r =
w1
, w2
, ., w
p(
wj
i/Ii∈ Sn
i/Ii∈ Sn
i/Ii∈ Sn
Un probl eme se pose dans ce calcul de probabilit´e. Lorsqu'un mot de la requˆete ne se retrouve dans
aucun document la probabilit´e associ´ee a ce mot est 0 et le r´esultat final se retrouve lui mˆeme a z´ero. Orcette situation tr es fr´equente pose un probl eme en pratique. En effet lorsque un mot de la requˆete n'est paspr´esent dans le corpus toutes les probabilit´es se retrouvent a z´ero, ce qui bloque la construction de l'arbre.
Le probl eme a ´et´e partiellement contourn´e en consid´erant que dans ce cas au moins un mot est pr´esentdans les documents de la feuille. Toutefois la probabilit´e minimale, d´ependante du nombre de mots dansles documents d'un nœud qui diff ere d'un nœud a un autre, pose un probl eme de normalisation.
Le crit ere d'arrˆet, devant ˆetre d´efini pour ´eviter d'obtenir autant de feuilles que d'individus a classer,est choisi dans nos exp´eriences comme ´etant une valeur seuil empirique du gain minimal en entropieautoris´e pour subdiviser un nœud.
ERES ET CONTEXTE D'´
Afin de pouvoir comparer syst emes et m´ethodes, des cam-
pagnes d'´evaluation sont organis´ees depuis quelques ann´ees. C'est le cas des campagnes francophonesAmaryllis dont le premier cycle s'est d´eroul´e de 1996 a 1997 et le second de 1998 a 1999. Le projetAmaryllis est le r´esultat de l'appel d'offres effectu´e par l'AUPELF-UREF (Agence Francophone pourl'Enseignement Sup´erieur et la Recherche). Les deux campagnes Amaryllis effectu´ees a ce jour ont ´et´eorganis´ees par l'INIST (INstitut de l'Information Scientifique et Technique). Les campagnes Amaryllissont organis´ees en plusieurs tˆaches. La tˆache principale concerne la recherche documentaire de type
ad-hoc (interrogation). Pour cette tˆache, des th emes sont fournis aux participants. Ces th emes contiennentdiff´erents champs textuels a partir desquels doivent ˆetre construites, automatiquement ou manuellement,les requˆetes. Ces th emes (voir tableau 15.1) sont compos´es de cinq ´el´ements :
1. le domaine situant la th´ematique g´en´erale ;
2. le sujet (le titre du th eme) ;
3. la question proprement dite ;
4. des compl´ements d'information pr´ecisant le domaine de recherche et une liste de concepts (liste
de termes d´elimitant la recherche).
Pour la campagne d'´evaluation Amaryllis'99, le fournisseur du corpus (que nous utilisons dans ce
m´emoire pour ´evaluer les diff´erentes m´ethodes envisag´ees) pour la tˆache
ad-hoc est l'OFIL (Observatoire
ecriture de requˆ
etes pour la recherche documentaire selon une m´
a base d'arbres de .
domaine :
International
sujet :
La s´eparation de la Tch´ecoslovaquie
question :
Pourquoi et comment avoir divis´e la Tch´ecoslovaquie et quelles ont
´et´e les r´epercussions ´economiques et sociales ?
compl´ements :
Prendre en compte les diff´erentes versions pr´esent´ees
concepts :
Partition de la Tch´ecoslovaquie, causes et modalit´es de la partition,
cr´eation de la Slovaquie et de la r´epublique Tch eque, points de vue, ´economie.
Table 15.1
Th eme no 1 de la campagne Amaryllis'99
Franc¸ais et International des Industries de la Langue). Leurs caract´eristiques sont disponibles dans letableau 15.2.
lemmes diff´erents
Table 15.2
Les corpus Le Monde ODx de la campagne Amaryllis'99 utilis´es au chapitre 3
Les r´ef´erentiels (liste des documents pertinents en fonction des th emes), correspondent a des jugementsformul´es par des experts du domaine (documentalistes, fournisseurs des corpus). Les ´evaluations d´ecritesdans ce m´emoire utilisent les deux jeux de th emes OT1 et OT2 (chacun contient 26 th emes) sur les corpusOD1 et OD2 de l'OFIL.
Evaluation en recherche documentaire.
L'´evaluation d'un syst eme est une tˆache subjective
puisqu'elle d´epend de r´ef´erentiels -listes des bonnes r´eponses- construits par des individus qui s'ac-cordent seulement dans 70% ou 80% des cas sur la pertinence ou non d'un document. Un syst eme derecherche documentaire propose une liste de documents a l'utilisateur a partir de l'ensemble des docu-ments du corpus cible. Cette liste contient des documents pertinents et d'autres non-pertinents. D'autrepart, certains documents pertinents ont ´et´e oubli´es et ne font pas partie de la liste. Toute recherche sub-divise donc le corpus en quatre sous-ensembles :
1. celui des documents pertinents trouv´es ;
2. celui des documents pertinents non trouv´es ;
3. celui des documents non-pertinents rapport´es a tort ;
4. celui des documents non-pertinents non rapport´es.
Parmi les objectifs d'un syst eme de recherche figurent la diminution du nombre de documents du casno 3 et du cas no 2. Les crit eres correspondants a ces deux objectifs se nomment "pr´ecision" et "rappel".
Leur d´efinition est donn´ee ci-dessous.
La pr´ecision d'une liste de documents est la proportion de documents pertinents dans
cette liste. Elle est d´efinie par :
nombre de documents pertinents trouv´
nombre de documents trouv´
Comme la liste de documents fournie en r´eponse a une requˆete est ordonn´ee, il est possible d'en mesurerla pr´ecision a diff´erents niveaux : pr´ecision des 5 premiers documents ("
quelle est la proportion de docu-ments pertinents parmi les 5 premiers ?"), pr´ecision des 20 premiers documents
etc. Dans la campagne
CHRISTIAN RAYMOND
Amaryllis, dont les donn´ees et les requˆetes sont utilis´ees pour les exp´eriences d´ecrites dans le chapitre 3,les diff´erents niveaux consid´er´es ont pour valeur : 5, 10, 15, 20, 30, 50, 100, 200, 5002.
Le rappel.
Le rappel rend compte de la quantit´e de documents pertinents rapport´es par rapport au
nombre de documents pertinents dans le corpus. Autrement dit, le rappel est le taux de documents per-tinents trouv´es par rapport au nombre de documents pertinents a trouver. Le rappel d'une liste est d´efinipar :
nombre de documents pertinents trouv´
nombre de documents pertinents
Notons qu'il suffit qu'un moteur de recherche propose a l'utilisateur tous les documents du corpus ciblepour que son rappel soit maximal (il vaut 1). Ce crit ere d'´evaluation ne peut donc ˆetre suffisant : lenombre de documents non pertinents rapport´es doit ˆetre pris en compte.
Une des mani eres de tenir compte a la fois du rappel et de la pr´ecision
d'un syt eme est d'interpoler les valeurs de pr´ecision correspondant a diff´erents niveaux de rappel. Lesniveaux standards de rappel varient entre 0 et 1 suivant un pas de 10%. La r egle d'interpolation utilis´eepour les campagnes TREC et Amaryllis d´efinit la pr´ecision pour un niveau de rappel i comme ´etant lavaleur maximale de pr´ecision pour tout niveau de rappel sup´erieur ou ´egal a i. Suivant cette d´efinitionune valeur de pr´ecision pour un rappel nul correspond au niveau maximal de pr´ecision obtenu pour unrappel quelconque.
ENRICHISSEMENT DE REQUˆ
ETES SELON UNE
CLASSIFICATION NON SUPERVIS´
EXPLOITATION D'UNE CLASSIFICATION POUR
SIAC permet de regrouper dans les feuilles de l'arbre, en fonction de la requˆete, les phrases issues
des documents retourn´es, "th´ematiquement proches" les unes des autres. Les questions pos´ees a chaquenœud de l'arbre ´etant de la forme : "les individus contiennent-ils le mot X ?" il est possible de repr´esenterles individus d'une feuille de l'arbre par une expression logique.
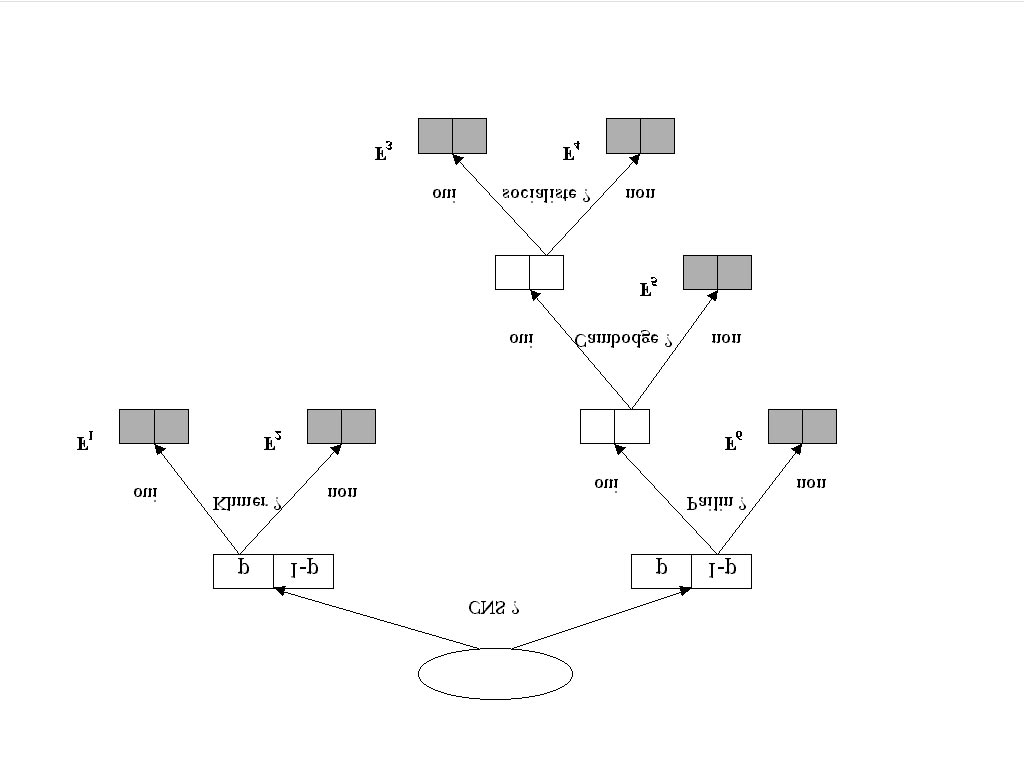
Figure 15.1
Arbre construit pour la requˆete no 23. (Amaryllis'99 - Corpus OFIL OD1 - Requˆetes OT1)
ecriture de requˆ
etes pour la recherche documentaire selon une m´
a base d'arbres de .
La feuille F3 (de la figure 15.1) peut ˆetre repr´esent´ee par l'expression :(NON(CNS)) ET (PAILIN) ET (CAMBODGE) ET (SOCIALISTE)L'expression logique repr´esentant une bonne feuille pourrait se r´ev´eler efficace pour enrichir la requˆete
initiale (voir requˆete 23 dans tableau 15.1). En effet, si l'arbre a r´eussi a construire une feuille poss´edantau final une grande proportion de documents pertinents, nous pouvons esp´erer d'une part que l'exploita-tion de cette expression, nous permette de positionner ces documents pertinents en tˆete de liste, d'autrepart que les mots trouv´es par l'arbre nous permettent de trouver de nouveaux documents pertinents.
Dans un premier temps, il faut trouver l'expression logique la plus utile ou performante, ce qui nousam ene a r´efl´echir sur ce qu'est une bonne feuille.
Dans un deuxi eme temps, vu que les expressions logiques tir´ees de l'arbre utilisent l'op´erateur NON, ilfaut r´efl´echir sur la mani ere d'int´egrer les mots pr´ec´ed´es de cet op´erateur dans un syst eme de recherchevectoriel qui ne prend pas en compte le fait qu'un mot n'est pas d´esir´e dans un document.
Et pour finir, une pond´eration pour les mots issus de l'expression logique doit ˆetre calcul´ee. En effet, cer-tains mots contribuent plus que d'autres au partitionnement donnant la feuille qui nous int´eresse. D'autrepart, ces mots peuvent ˆetre des mots existants dans la requˆete originelle ou bien des mots nouveaux.
Le r´egime de Phnom-Penh (P.P.C.), conseil national suprˆeme (C.N.S.)
le pouvoir royal des khmers rouges, immigr´es vietnamiens
les accords de Paris, l'autorit´e provisoire des nations unies.
Table 15.3
Formulation de la requˆete 23 a partir de la section "concept" du th eme no 23
RECHERCHE DE LA MEILLEURE FEUILLE
Pertinence d'une feuille.
L'objectif premier est de repositionner les documents pertinents en tˆete
des r´eponses (am´elioration de la pr´ecision sur les premiers documents) plutˆot que d'augmenter leurnombre (rappel). Les meilleures feuilles sont alors s´electionn´ees en fonction du crit ere li´e a cet objectif :la pr´ecision. Il est possible d'utiliser la pr´ecision globale d'une feuille :
nombre de documents pertinents dans la f euille
nombre total de documents dans la f euille
ou la pr´ecision sur les premiers documents. La pr´ecision globale privil´egie trop les feuilles peu peupl´ees.
En effet, une feuille ne contenant qu'un document mais pertinent sera consid´er´ee meilleure qu'une feuillecontenant 20 documents dont 19 sont pertinents. Il est pourtant l´egitime de penser que l'expressionbool´eenne permettant d'acc´eder a cette feuille va influer sur un plus grand nombre de documents et ˆetreplus efficace dans l'op´eration de repositionnement des documents pertinents en tˆete de liste, notammentlorsque la feuille choisie poss ede une pr´ecision sur les premiers documents sup´erieure a la liste de do-cuments avant classification. Il est vrai qu'inversement, une feuille contenant un seul document qui esten outre pertinent aura une moins bonne pr´ecision a 5 documents qu'une feuille contenant 2 documentspertinents parmi les 5 premiers puis 200 documents non pertinents ensuite. La s´election de la meilleurefeuille n'est donc pas un probl eme simple. Dans un premier temps, c'est toutefois la pr´ecision sur lespremiers documents qui a ´et´e choisie pour les ´evaluations.
es automatique
a la meilleure feuille.
L'utilisation des donn´ees de la campagne Amaryl-
lis nous ont permis d'exp´erimenter ces m´ethodes d'enrichissement de requˆetes, notamment en pouvantcibler la meilleure feuille au sens que nous avons d´efini dans la section pr´ec´edente. Cependant, cet acc es
a la meilleure feuille en fonction du r´ef´erentiel doit devenir non-supervis´e afin de rendre la m´ethode
utilisable en pratique. Dans un premier temps, il faut voir si l'acc es a la meilleure feuille peut ˆetre trouv´esimplement en utilisant les variables g´en´er´ees par l'arbre de d´ecision, tels la valeur du crit ere utilis´e dansle choix de la meilleure question a poser, la probabilit´e associ´ee a chaque feuille, ou (et) des valeursfacilement calculables a posteriori comme la population de chacune des feuilles, leur profondeur dansl'arbre, etc.
CHRISTIAN RAYMOND
Une analyse en composantes principales effectu´ee sur les diff´erentes valeurs obtenues par la cr´eationd'arbres sur les jeux de requˆetes OT1 et OT2 nous aide a d´eceler des corr´elations entre certains pa-ram etres et la feuille qui nous int´eresse, et a visualiser leur influence. Le principe de cette m´ethoded'analyse de donn´ees est d'obtenir une repr´esentation approch´ee des donn´ees dans un sous-espace dedimension faible (3 dimensions). Ces analyses ont port´e sur les donn´ees obtenues par les arbres g´en´er´esgrˆace aux jeux de requˆetes OT1 sur les corpus OD1 et OD2 et OT2 sur le corpus OD1. Les param etressoumis a l'ACP sont les suivants :
– la pertinence : valeur binaire, 1 pour la meilleure feuille, 0 pour les autres ;– Nb Questions : nombre de questions pos´ees (la profondeur de la feuille dans l'arbre) ;– Gini : valeur binaire, 1 pour l'indice le plus fort, 0 pour les autres ;– proba : valeur binaire, 1 pour la probabilit´e (d´efinie en 1.3) la plus forte, 0 pour les autres ;– population : nombre de documents (ou de phrases suivant la nature des individus class´es) dans la
Cette analyse ne permet pas de d´egager de corr´elations fortes entre les param etres et la pertinence
d'une feuille (voir la matrice 2.2). Le graphe 15.2 confirme la non-corr´elation de ces param etres avecla pertinence des feuilles, les vecteurs repr´esentant la pertinence ´etant tr es ´eloign´e de ceux portant lesautres param etres. D'autres ACP avec d'autres param etres seront r´ealis´ees et apporteront peut ˆetre und´ebut de r´eponse. Ce probl eme d'acc es a la meilleure feuille ´etant complexe, une ´etude plus longue doit
ˆetre effectu´ee.
Table 15.4
Matrice des corr´elations
ECRITURE DE LA POND´
ERATION : QUELQUES
es par le traitement de la n´
Outre le fait que l'expression lo-
gique tir´ee de l'arbre de classification poss ede l'op´erateur NON, ce qui nous am ene a r´efl´echir sur sonint´egration dans le mod ele vectoriel, certaines requˆetes peuvent exprimer cette "n´egation" de fac¸on ex-plicite (exemple dans la requˆete 15.3 de TREC 3), le traitement de la n´egation est donc une perspectiveint´eressante en dehors de son utilit´e dans notre cas. Dans de nombreux syst emes de recherche, l'objet"truck recalls" ne subira pas de traitement sp´ecifique et ne sera pas vu comme relevant de la n´egation.
Le mot "Truck" figurera dans la requˆete au mˆeme titre que "car" et les syst emes chercheront ´egalementdes documents parlant de r´eparation de camion. Il peut ˆetre choisi d'´eliminer syst´ematiquement tousles mots de ce type, mais cette technique ´elimine du mˆeme coup le potentiel de l'information qui ´etaitpropos´ee. Toutefois certaines tentatives d'exploitation de ces mots "n´egatifs" ont ´et´e faites. [Satoh et al.,1994] ´etiquettent manuellement les mots des requˆetes avec des op´erateurs bool´eens avant d'appliqueraux mots "n´egatifs" un poids oppos´e a la valeur tf.idf du mot (aucune ´evaluation comparative n'est four-nie par les auteurs). [He et al., 1996] supposent que si un terme "n´egatif" de la requˆete apparaˆıt dans undocument, le poids final devrait ˆetre r´eduit. [He et al., 1996] divisent le poids final par la racine carr´ee dunombre de termes n´egatifs plus un. Les auteurs ne donnent pas de raisons autre qu'empirique a ce choix.
Ils constatent une augmentation de la pr´ecision sur les 10 premiers documents, mais la pr´ecision totalebaisse par rapport a la non prise en compte de ces termes.
ecriture de requˆ
etes pour la recherche documentaire selon une m´
a base d'arbres de .
Figure 15.2
Biplot sur les axes 1 et 2 (67% )
"A relevant document will specify major or minor reasons for automobile recalls by car manufacturers.
Documents that discuss truck recalls are not relevant"
Figure 15.3
champ narratif du topic no 397 de TREC-7
Afin de comprendre o u se situe le traitement de la n´egation, notons que pour chaque mot d'une requˆeteet pour chaque document ´evalu´e, il existe quatre cas de figure pouvant ˆetre rencontr´es :
1. le document contient ce mot que nous souhaitons voir apparaitre dans le document ;
2. le document ne contient pas ce mot alors que nous souhaitons le voir apparaitre dans le document ;
3. le document contient le mot que nous ne souhaitons pas voir apparaitre dans le document ;
4. le document ne contient pas le mot que nous ne souhaitons pas voir apparaitre dans le document.
Actuellement, et mˆeme en dehors du traitement de la n´egation (exclusion des cas no 2 et no 3), seul un
cas est trait´e a notre connaissance, le cas no 1, par les syst emes vectoriels de recherche documentaire. Laprise en compte de la n´egation, nous oblige a r´efl´echir sur le traitement de ces quatre cas.
Deux principaux probl emes se r´ev elent :
– ´evaluer l'utilit´e des quatre cas a traiter : certains sont peut-ˆetre corr´el´es ;– trouver une pond´eration efficace pour les cas s´electionn´es, compatible avec le mod ele vectoriel et
entre elles.
Avant une ´etude plus complexe, le cas no 3 a ´et´e choisi dans le traitement de la n´egation. Car il est plusfacile de tirer parti, pour la pond´eration, d'un mot lorsqu'il est pr´esent dans le document que lorsqu'il estabsent.
eration des mots.
La pond´eration des mots tir´es de l'expression bool´eenne associ´ee a la
meilleure feuille peut ˆetre obtenue de deux fac¸ons :
1. a partir des donn´ees du corpus ;
2. a partir des param etres de l'arbre.
La premi ere m´ethode poss ede un avantage sur la seconde. N'existant pas a notre connaissance de pond´erationpour les mots "n´egatifs", si celle-ci est calcul´ee a partir des param etres de l'arbre, il ne sera pas possible
CHRISTIAN RAYMOND
de l'appliquer a des mots "n´egatifs" ne provenant pas de l'arbre, mais directement de la requˆete commedans l'exemple de la figure 15.3.
a partir des param
etres de l'arbre.
Les mots de l'expression bool´eenne
peuvent ˆetre regroup´es en deux familles :
1. le mot est nouveau, il n'´etait pas pr´esent dans la requˆete originelle ;
2. le mot est un mot de la requˆete.
Si le mot est nouveau :les mots de l'expression logique n'ont pas la mˆeme contribution a la cr´eation de la r´epartition qui aconduit a ce d´eveloppement de l'arbre. Cette contribution pourrait ˆetre ´evalu´ee en fonction de certainsparam etres de l'arbre comme le gain en entropie obtenu avec ce mot ou la profondeur de l'arbre a laquellese situe ce mot. On peut l´egitimment penser que la profondeur informe sur la contribution du mot a laformation de la feuille finale. Le premier mot choisi, qui donne le meilleur gain en entropie, permet der´ealiser la meilleure r´epartition. Les autres raffinent cette partition jusqu'a obtenir la feuille finale. Doncplus le mot est proche de la racine de l'arbre plus sa contribution doit ˆetre importante. Sa pond´erationdoit tenir compte de cet aspect, elle peut ˆetre de la forme :
eration 1 =
log(prof ondeur du mot + 1)
La profondeur du mot dans l'arbre ne suffit pas pour calculer une pond´eration d´efinitive. Car deux arbresne sont pas susceptibles d'aboutir a un partitionnement de mˆeme qualit´e. Deux mots de mˆeme profondeurprovenant de deux arbres diff´erents ne contribuent pas a la mˆeme qualit´e de r´epartition. Cela est vrai
´egalement sur un seul et mˆeme arbre o u deux mots de mˆeme profondeur (et donc sur deux branches
diff´erentes) ne permettent pas de r´ealiser des partitions de qualit´es identiques. La qualit´e d'une partition
´etant mesur´ee dans les arbres de d´ecision par l'entropie, une composante fonction de celle ci doit ˆetre
incorpor´ee dans le calcul de la pond´eration du mot qui a conduit a cette partition, de la forme :
gain en entropie
eration 2 =
gain max en entropie
Ce qui nous conduit a une pond´eration absolue du style :
gain en entropie
erationf inale =
(gain max en entropie) ∗ log(prof ondeur du mot + 1)
Une valeur positive de cette pond´eration serait attribu´ee aux mots "positifs" et une valeur n´egative auxmots "n´egatifs".
Dans le cas o u le mot est un mot de la requˆete :
le mot n'est pas inject´e dans la nouvelle requˆete, c'est la pond´eration originelle de ce mot qui doit ˆetrerecalcul´ee. Selon la situation, le poids du mot doit ˆetre revu a la hausse, c'est le cas o u le mot trouv´e parl'arbre a la mˆeme valeur logique que dans la requˆete4, o u a la baisse si la valeur logique du mot dansl'arbre est oppos´ee5 par rapport au mot dans la requˆete. L'arbre nous donne alors la possibilit´e de corrigeret d'adapter les pond´erations des mots de la requˆete. Une combinaison de la pond´eration originelle et dela pond´eration du mot tir´ee de l'arbre peut ˆetre faite en les additionant. Le poids du mot dans la nouvellerequˆete serait alors r´e´evalu´e a la hausse ou a la baisse conform´ement aux hypoth eses pr´ec´edentes.
a partir des donn´
ees du corpus.
La pond´eration des mots "positifs" tir´es de
l'arbre est calcul´e comme les autres mots "positifs" de la requˆete originelle selon le crit ere TF.IDF utilis´edans SIAC. Ce crit ere TF.IDF donne l'importance d'un mot de fac¸on convenable mˆeme pour un mot"n´egatif". Afin que sa pond´eration exprime un point de vue n´egatif par rapport au document, il a ´et´echoisi d'opposer sa valeur.
eration mots n´
egatif s = −T F.IDF
ecriture de requˆ
etes pour la recherche documentaire selon une m´
a base d'arbres de .
Cela permet de changer de sens la composante du vecteur requˆete associ´ee a ce mot par rapport a lacomposante du vecteur document, qui elle, reste positive. La similarit´e entre le document et la requˆetesera ainsi adapt´ee en fonction de la pr´esence ou non des mots "n´egatifs" dans le document.
Dans le cas particulier o u le mot tir´e de l'expression bool´eenne repr´esentant la meilleure feuille estpr´esent dans la requˆete originelle :
– le poids du mot sera r´e´evalu´e a la hausse (en valeur absolue) si les mots sont de mˆeme valeur logique
(tous deux "positifs" (ou "n´egatifs") dans la requˆete et dans l'arbre) d'un coefficient 2. Le mot auraun poids TF (Term Frequency) dans la requˆete doubl´e ;
– le mot sera ´elimin´e de la requˆete si les mots ont une valeur logique oppos´ee, un des mots aura
un poids T F.IDF , l'autre −T F.IDF , le poids d´efinitif du mot au moment de la recherche vau-dra :T F.IDF − T F.IDF soit z´ero.
Au premier abord cette m´ethode de pond´eration, bien qu'ayant l'avantage de pouvoir ˆetre utilis´ee pourles mots "n´egatifs" ne provenant pas de la m´ethode de classification, parait ˆetre un peu trop rigide. Lar´e´evaluation des poids ´etant moins pr´ecise, le poids d'un mot ´etant doubl´e ou annul´e. Cette m´ethode plussimple a formuler a ´et´e test´ee dans le chapitre suivant.
CLASSIFICATION DES PHRASES DES DOCUMENTS ET
Dans un premier temps l'exploitation des mots de l'arbre pour l'enrichissement des requˆetes a ´et´e test´e
avec les mots pour lesquels les phrases contenues dans la meilleure feuille ont r´epondu OUI. L' arbrene permet pas toujours d'isoler une forte proportion de documents pertinents dans une feuille. Dans uncertain nombre de cas, la feuille poss´edant les phrases de documents ayant r´epondu NON a toutes lesquestions pos´ees est :
– d'une part la plus peupl´ee (dans tous les cas), car elle regroupe les individus que l'arbre n'a pas
r´eussi a classer ;
– d'autre part (dans les trois quart des cas), la feuille poss´edant les meilleurs crit eres d'´evaluation. Ce
qui implique que l'expression bool´eenne caract´erisant cette feuille est constitu´ee exclusivement demots pr´ec´ed´es de l'op´erateur NON.
Cette derni ere remarque implique que le nombre de requˆetes pouvant ˆetre enrichies avec des mots "po-sitifs" est limit´e (8 requˆetes sur 26 pour le corpus OD1, 7 pour le corpus OD2). Les r´esultats suivantssont les r´esultats d'une nouvelle recherche avec les nouvelles requˆetes enrichies avec les mots en ques-tions. Le poids des mots est alors calcul´e comme les autres mots de la requˆetes suivant le crit ere TF.IDFimpl´ement´e dans S.I.A.C. L'objectif premier ´etant d'am´eliorer la pr´ecision, sans toutefois perdre en rap-pel, la nouvelle recherche est effectu´ee sur un nouveau corpus constitu´e par les documents retourn´esavec la premi ere recherche (lignes not´ees "Ajout" dans les tableaux r´esultats 15.5 et 15.6). Ce qui a pourbut de r´eordonner les documents. Toutefois le repositionnement des documents avec la requˆete origi-nelle fait chuter les performances. En effet les mots de la requˆete sont maintenant tr es repr´esent´es dansle corpus constitu´e des documents rapport´es par la premi ere recherche, ce qui a pour effet de modi-fier le crit ere IDF et d'influer sur l'ordre des documents et g´en´eralement le rendre moins performant.
Dans le cas d'un r´eordonnancement des documents les valeurs IDF du corpus initial semblent devoir
ˆetre conserv´ees. Dans l'attente de cette modification le nouveau r´eordonnancement avec la requˆete non-
modifi´e sert de r´ef´erence dans les tableaux suivants (lignes not´ees "R´ef´erence" dans le tableau 15.5).
Une autre exp´erience sur chaque corpus montre les r´esultats avec le poids du ou des mots ajout´es muti-pli´e par un facteur empiriquement choisi au vu des r´esultats qui a tendance a montrer qu'une nouvellepond´eration doit ˆetre ´etudi´ee (lignes not´ees "Ajout X" dans le tableau 15.5 et 15.6 ou X est suivi dufacteur appliqu´e au poids des nouveaux mots de la requˆete).
Le tableau 15.6 montre les r´esultats des pr´ec´edentes exp´eriences sur le corpus complet. Ces exp´eriences,
ont quant a elles, des incidences sur le rappel. Les requˆetes ´etant diff´erentes, la liste retourn´ee par le mo-teur de recherche en est chang´ee.
CHRISTIAN RAYMOND
R´ef´erence OD1
R´ef´erence OD2
Table 15.5
R´esultats du r´eordonnancement des documents sur les requˆetes enrichies avec les mots positifs - Amaryllis'99)
R´ef´erence OD1
R´ef´erence OD2
Table 15.6
R´esultats de la nouvelle recherche des documents sur les requˆetes enrichies avec les mots positifs - Amaryllis'99)
Dans cette construction des arbres, ce sont les phrases des documents qui sont class´ees, les feuilles
de l'arbre sont donc peupl´ees de phrases. L'arbre a ´et´e construit au d´epart pour classer et segmen-ter th´ematiquement les documents (voir [Bellot et El-B eze, 2001]). Des documents abordant plusieursth´ematiques sont segment´es et leurs phrases se retrouvent dans des feuilles diff´erentes. Feuilles quisont repr´esent´ees par des expressions bool´eennes diff´erentes. Les deux expressions logiques, tir´ees d'unarbre binaire, poss edent au moins un mot en commun mais pr´ec´ed´e d'un op´erateur oppos´e. Cette ca-ract´eristique ne pose pas de gros probl emes pour les mots "positifs". Le fait d'ajouter un mot positif dela requˆete rep´esentant la feuille contenant des phrases de documents pertinents permet de favoriser cesdocuments lors d'une nouvelle recherche ind´ependamment de la pr´esence ou non de ce mot dans lesautres phrases de ces documents rang´es dans d'autres feuilles. Dans le cas d'ajout de mots "n´egatifs"la pr´esence6 de ces mots dans des phrases rang´ees dans une autre feuille7 peut annuler voire inverser ler´esultat attendu, la recherche s'effectuant sur les documents entiers et non sur les phrases.
ecriture de requˆ
etes pour la recherche documentaire selon une m´
a base d'arbres de .
Figure 15.4
Informations sur les mots obtenus par les arbres fond´es sur l'entropie classant les phrases
CLASSIFICATION DES DOCUMENTS ET
Pour rem´edier au probl eme pos´e par les mots "n´egatifs", nous avons modifi´e les param etres de l'arbre
de d´ecision. Effectivement, l'objectif ici n'´etant plus de segmenter les documents pour trouver desfronti eres th´ematiques, mais plutˆot pour arriver a s´eparer au mieux les documents pertinents des non-pertinents, nous avons effectu´e la classification sur les documents dans leur int´egralit´e et non plus surdes phrases. Il se trouve que dans cette configuration l'arbre ne se d´eveloppe pas. Ceci est certainementdˆu a un mauvais traitement de la fonction logarithme sur de tr es faibles valeurs de probabilit´e manipul´eesdurant le calcul de l'entropie. Toutefois cela ouvre plusieurs questions, notamment sur :
– le calcul de probabilit´e associ´e a l'arbre de d´ecision ;– le traitement des mots absents des documents dans ce calcul de probabilit´e ;– le crit ere de s´election de la meilleure question possible a chaque nœud de l'arbre.
Afin de pallier a ce probl eme, nous avons donc utilis´e le crit ere de Gini en lieu et place de l'en-
tropie pour la s´election de la meilleure question possible a chaque nœud de l'arbre. Ces crit eres sontfortement corr´el´es, mais celui de Gini n'utilise pas la fonction logarithme. Ce nouveau crit ere permet led´eveloppement des arbres sur les documents. Les r´esultats obtenus avec l'ajout des mots, issus des arbres,aux requˆetes sont visibles sur les figures 15.5 et 15.6. La classification sur les documents obtenue donnelieu a un arbre beaucoup moins d´evelopp´e qu'en classant les phrases (avec une profondeur moyenne de2 contre 5 ou 6 avec les phrases) . Comme on peut le remarquer dans le tableau 15.7 beaucoup de motstrouv´es par l'arbre sont des mots de la requˆete, ce qui laisse penser qu'une pond´eration calcul´ee a partirde l'arbre serait plus appropri´ee pour en tirer profit. Toutefois, un test effectu´e avec le crit ere de Ginisur la classification des phrases montre que les arbres produits ne se d´eveloppent pas plus qu'en classantles documents, ce faible d´eveloppement ne provient donc pas forc´ement du fait que nous classons desdocuments, mais peut ˆetre du crit ere de Gini. Un travail particulier devra ˆetre consacr´e au choix du crit erede d´ecision.
CONCLUSION ET PERSPECTIVES
Les r´esultats obtenus montrent que l'exploitation des mots tir´es de l'expression bool´eenne conduisant
a la meilleure feuille augmente la pr´ecision. L'exploitation des mots "positifs" a entrain´e des am´eliorations
significatives de la pr´ecision de l'ordre de 10%. Les r´esultats de l'utilisation des mots "n´egatifs" sontmoins significatifs, entrainant une baisse de la pr´ecision de 1% a 3%. L'enrichissement au moyen desmots de l'expression bool´eenne n´ecessite, pour ˆetre exploit´e au mieux, une ´etude plus longue portantnotamment sur les nombreuses perspectives de d´eveloppement et d'am´eliorations qui ont ´et´e d´egag´ees.
CHRISTIAN RAYMOND
Figure 15.5
Courbe nombre de documents/pr´ecision (requˆetes enrichies OT1 - Corpus OD1 - Amaryllis'99)
Figure 15.6
Courbe Rappel/Pr´ecision (requˆetes enrichies OT1 - Corpus OD1 - Amaryllis'99)
elioration de la construction de l'arbre de classification.
La m´ethode de classifica-
tion utilis´ee permet de classer th´ematiquement les r´esultats d'une requˆete. La m´ethode de classificationpourrait ˆetre adapt´ee au mieux pour atteindre cet objectif : isoler au mieux les documents pertinents dansune feuille, les non-pertinents dans d'autres. Ceci passe par des am´eliorations sur le crit ere de d´ecisionde l'arbre. Celui-ci a montr´e qu'il est assez influent dans le r´esultat de la classification (diff´erence deprofondeur et du choix des mots). Dans des cas particulier, [Jun et al., 1997] assurent que dans certainscas, un nouveau crit ere appel´e "gain normalis´e" permet une meilleure r´epartition des individus.
ecriture de requˆ
etes pour la recherche documentaire selon une m´
a base d'arbres de .
Figure 15.7
Informations sur les mots obtenus par les arbres fond´es sur le cit ere de Gini classant les documents
Cela passe aussi par le calcul de la probabilit´e intervenant dans le crit ere de d´ecision (d´efini dans 1.3).
Des am´eliorations peuvent ˆetre obtenues, d'une part en r´esolvant d'une mani ere plus satisfaisante leprobl eme soulev´e du calcul de la probabilit´e d'un mot absent dans le corpus, d'autre part en modifiant laformule elle-mˆeme. Des travaux sur un calcul de probabilit´e faisant intervenir des cat´egories syntaxiquesou s´emantiques proches du mot choisi comme question sont en cours. Ces mots-questions pourraient
´egalement ˆetre choisi parmi des cat´egories non-index´ees actuellement, telles les nombres, les ajectifs et
ere de choix de la meilleure feuille.
Le crit ere de choix de la meilleure feuille difficile
a d´eterminer pour satisfaire notre objectif, doit ˆetre approfondi. Le crit ere utilis´e dans ce m´emoire n'´etant
pas id´eal, il est probable qu'il soit en partie responsable des r´esultats peu significatifs de l'exploitationdes mots "n´egatifs".
Perspectives sur la pond´
eration et le traitement de la n´
Le reclassement des
documents retourn´es par le syst eme entraˆıne une baisse des r´esultats comme l'indique le tableau 15.5.
Les valeurs des index du corpus total devront ˆetre conserv´ees. De plus, les ´evaluations montrent queles pond´erations des mots "positifs" de l'arbre calcul´ees en fonction du corpus ne sont pas optimalesmˆeme si elles sont efficaces. En effet, de meilleurs r´esultats sont obtenus en augmentant leur poids via unfacteur trouv´e empiriquement au vu des ´evaluations, mais ceci est peut ˆetre li´e au ph´enom ene pr´ec´edent,
a savoir le changement d'index. Si ce n'est pas le cas, des ´evaluations avec les pond´erations calcul´ees a partir des donn´ees des arbres devront ˆetre faites. La pond´eration utilis´ee par les mots "n´egatifs" par
contre n'a pas permis d'am´elioration, une pond´eration de la forme qui a ´et´e propos´ee en 15.3 devra ˆetre
Ces perspectives ouvrent la voie vers un travail de th ese afin de faire ´evoluer le crit ere de pond´eration
des termes classiquement employ´e en recherche documentaire et particuli erement pour l'int´egration etl'utilisation de mots "n´egatifs".
1. Dans notre cas, k=2, la classe des documents pertinents et celle des documents non pertinents
2. Le r´ef´erentiel est limit´e a 250 documents a cause du coˆut li´e a sa construction
3. Text REtrieval Conference, campagne internationale d'´evaluation de syst emes de recherche documentaire
4. Soit le mot de la requˆete est "positif" (nous souhaitons le retrouver dans les documents) et le mot est pr´ec´ed´e de l'op´erateur OUI dans
l'expression bool´eenne tir´ee de l'arbre, soit le mot de la requˆete est "n´egatif" (nous souhaitons ne pas le retrouver dans les documents) et lemot est pr´ec´ed´e de l'op´erateur NON dans l'expression bool´eenne tir´ee de l'arbre
5. cas o u le mot est "positif" dans la requˆete et "n´egatif" dans l'expression bool´eenne ou inversement
CHRISTIAN RAYMOND
6. ce qui est fortement probable a moins que toutes les phrases d'un mˆeme document se retrouvent dans la mˆeme feuille (document ne
parlant que d'une th´ematique).
7. ces individus ont peut ˆetre r´epondus OUI l a o u les phrases de la meilleure feuille ont r´epondu NON.
[Attar et Fraenkel, 1977] Attar, R. et Fraenkel, A. (1977). Local feedback in full-text retrieval systems.
Journal of the ACM, 24(3) :397 a 417.
[Baeza-Yates et Ribeiro-Neito, 1999] Baeza-Yates, R. et Ribeiro-Neito, B. (1999). Modern information
retrieval. ACM press books, addison-wesley edition.
[Bellot, 2000] Bellot, P. (2000). M´ethode de classification et segmentation locales non supervis´ees pour
la recherche documentaire. PhD thesis, Universit´e d'Avignon et des pays du Vaucluse.
[Bellot et El-B eze, 2001] Bellot, P. et El-B eze, M. (2001). Classification et segmentation de textes par
arbres de d´ecision, volume 20, chapter 3, page 397 a 424. Technique et Science Informatiques (TSI),editions herm es edition.
[Breiman et al., 1984] Breiman, L., Friedman, J., Olshen, R., et Stone, C. (1984). Classification and
regression trees.
[Harman, 1992] Harman, D. (1992). Ranking algorithms, page 363 a 392.
[He et al., 1996] He, J., Xu, J., Chen, A., Meggs, J., et Gey, F. C. (1996). Chinese information retrieval
at trec5. Technical report, UC DATA University of California Berkeley.
[Jun et al., 1997] Jun, B. H., Kim, C. S., et Kim, J. (1997). A new criterion in selection and discretization
of attributes for the generation of decision trees. IEEE transactions on pattern analysis and machineintelligence, 19(12).
[Kuhn et De Mori, 1995] Kuhn, R. et De Mori, R. (1995). The Application of Semantic Classification
Trees to Natural Language Understanding, volume 17, chapter 5, page 449 a 460. IEEE Transactionson Pattern Analysis and Machine Intelligence.
[Kwok, 1996] Kwok, K. (1996). A new method of weighting query terms for ad-hoc retrevial. actes
de ACM/SIGIR'96 Conference on Research and Development in Information retrevial, Zurich Suisse,page 187 a 195.
[Qiu et Frei, 1993] Qiu, Y. et Frei, H. (1993). Concept based query expansion, page 160 a 169. actes de
ACM/SIGIR'93 Conference on Research and Development in Information Retrieval.
[Robertson et Sparck-Jones, 1976] Robertson, S. et Sparck-Jones, K. (1976). Relevance weighting of
search terms, volume 27, page 129 a 146.
[Salton, 1971] Salton, G. (1971). The SMART retrieval system. Pre Hall, Englewood Cliffs NJ,USA.
[Salton et Allan, 1994] Salton, G. et Allan, J. (1994). Automatic text decomposition and structuring.
actes de RIAO'94, page 6 a 29.
[Satoh et al., 1994] Satoh, K., Okumura, A., et Yamabana, K. (1994). Information retrieval system for
trec3. In Text REtrieval Conference.
[Sparck-Jones, 1972] Sparck-Jones, K. (1972). A statistical interpretation of term specificity and its
application to retriever. Journal of documentation, 28(1) :11 a 21.
Source: http://www.irisa.fr/texmex/people/raymond/pub/Dea.pdf
PRODUCT MONOGRAPH Solifenacin Succinate Tablet, 5 mg, 10 mg Urinary antispasmodic 675 Cochrane Drive, Suite 500, West Tower Markham, ON L3R 0B8 Date of Revision: VESICARE® Product Monograph Table of Contents PART I: HEALTH PROFESSIONAL INFORMATION. 2 SUMMARY PRODUCT INFORMATION . 2 INDICATIONS AND CLINICAL USE. 2 CONTRAINDICATIONS . 2 WARNINGS AND PRECAUTIONS. 3 ADVERSE REACTIONS. 6 DRUG INTERACTIONS . 8 DOSAGE AND ADMINISTRATION. 9 OVERDOSAGE . 10 ACTION AND CLINICAL PHARMACOLOGY . 10 STORAGE AND STABILITY. 13 DOSAGE FORMS, COMPOSITION AND PACKAGING . 13
4.4 Welche Krankheitsstadien gibt es? Stadium 1: Die Krankheit entwickelt sich aus einem normalen Leistungsniveau. Stadium 2: In der Folge nimmt die/der Betroffene leichte Störungen wahr. Die Merkfähigkeit und das Gedächtnis sind beeinträchtigt. Namen und Termine werden vergessen. Bei manchen Situationen fehlt die Erinnerung und öfters werden Dinge verlegt.